数据仓库【十三】:数据仓库选型,Doris
背景
我们已经维护了 Kylin 和 Druid 两个开源 OLAP 系统,Kylin 主要满足离线固化多维分析的需求,Druid 主要满足实时多维分析的需求。
所谓的固化多维分析,指需要提前预定义维度和指标,然后查询时需要根据定义好的维度和指标进行查询,这样就无法满足即席的灵活多维分析需求,比如任意字段聚合,任意多表 Join。
还有一点就是 Kylin 和 Druid 都是基于预计算的系统,没有保留明细数据,无法进行明细查询。(注:Kylin 和 Druid 都可以通过一定的间接方式实现明细查询,但限制较多)
用户需求
- 灵活多维分析
- 明细+聚合
- 主键更新
随着我们用户上面 3 类的需求越来越多,我们决定在 2018 年初的时候调研当时开源的 ROLAP 系统,并进行落地。
Why Not Other ROLAP
我们当时主要调研了 SQL on Hadoop,ClickHouse,SnappyData,TiDB,Doris 等系统, 这些系统都是优秀的开源系统,并且都有其适用场景。我们在选型时主要从功能,架构,性能,易用性,运维成本等几个维度去考虑。
下面我先介绍下我们为什么没有选择这些系统,再介绍我们为什么选择了 Doris。
- SQL on Hadoop 系统:无法支持更新,性能也较差。
- TiDB: TiDB 虽然当初号称可以支撑 100%的 TP 和 80%的 AP,但是架构设计主要是面向 TP 场景,缺少针对 AP 场景专门的优化,所以 OLAP 查询性能较差,TiDB 团队目前正在研发专门的 OLAP 产品:TiFlash,TiFlash 具有以下特点:列存,向量化执行,MPP,而这些特点 Doris 也都有。
- SnappyData:SnappyData 是基于 Spark + GemFire 实现的内存数据库,机器成本较高,而我们机器资源很有限,此外 SnappyData 的计算是基于 JVM 的,会有 GC 问题,影响查询稳定性。
- ClickHouse:Clickhouse 是一款单机性能十分彪悍的 OLAP 系统,但是当集群加减节点后,系统不能自动感知集群拓扑变化,也不能自动 balance 数据,导致运维成本很高,此外 Clickhouse 也不支持标准 SQL,我们用户接入的成本也很高。
Why Doris
对我们用户来说,Doris 的优点是功能强大,易用性好。 功能强大指可以满足我们用户的需求,易用性好主要指兼容 Mysql 协议和语法,以及Online Schema Change。 兼容 Mysql 协议和语法让用户的学习成本和开发成本很低, Online Schema Change 也是一个很吸引人的 feature,因为在业务快速发展和频繁迭代的情况下,Schema 变更会是一个高频的操作。
对我们平台侧来说,Doris 的优点是易运维,易扩展和高可用:
- 易运维指 Doris 无外部系统依赖,部署和配置都很简单。
- 易扩展指 Doris 可以一键加减节点,并自动均衡数据。
- 高可用值 Dors 的 FE 和 BE 都可以容忍少数节点挂掉。
典型应用
变化维表 Join
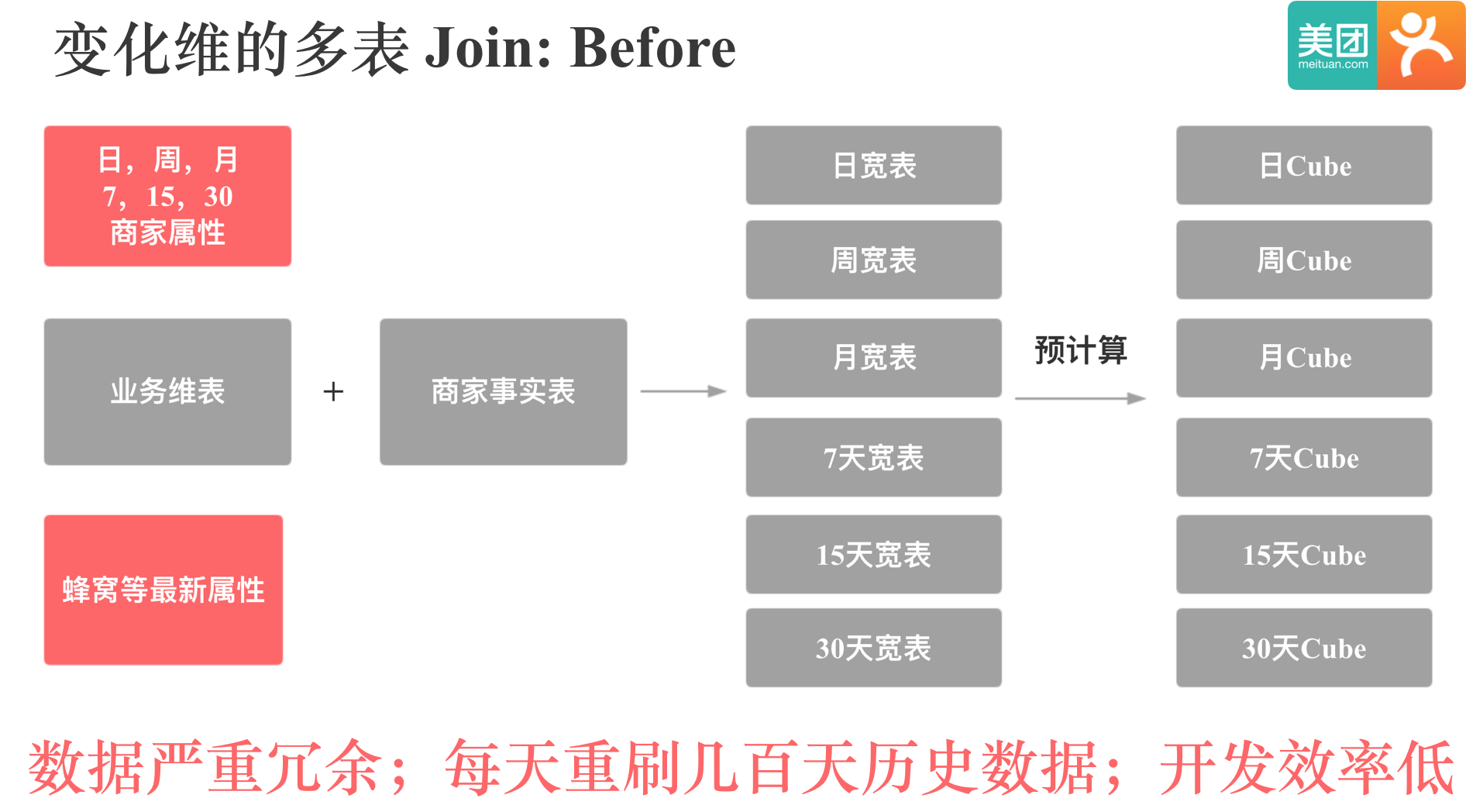
变化维表的 Join 是我们外卖业务很典型的一个应用,我们外卖中的蜂窝,商家类型等维表属性会经常更新,并且需要用最新的维表属性去关联商家事实表的历史数据。 还有一点是外卖的商家属性是按照日,周,月,7,15,30 这 6 个时间口径统计的,而且这里面的周,月,7,15,30 不能按天直接累加,所以之前在 MOLAP 系统中,用户需要先建 6 张宽表,再基于 6 张宽表构建 6 个 Cube。 为了满足用最新的维表数据去关联事实表的历史数据的需求,就需要每天重刷几百天的历史数据。其实用户的高频查询都是近 1 个月的数据,但是为了满足极个别查很久历史数据的需求,就必须得重刷几百天的历史。 这样就会浪费大量的计算资源,而且数据冗余比较严重,开发效率低下。

有了 Doris 之后,我们就只需要按天同步事实表和维表,然后查询时现场 Join 就可以。 不需要每天重刷历史数据,开发效率也会提升很多。
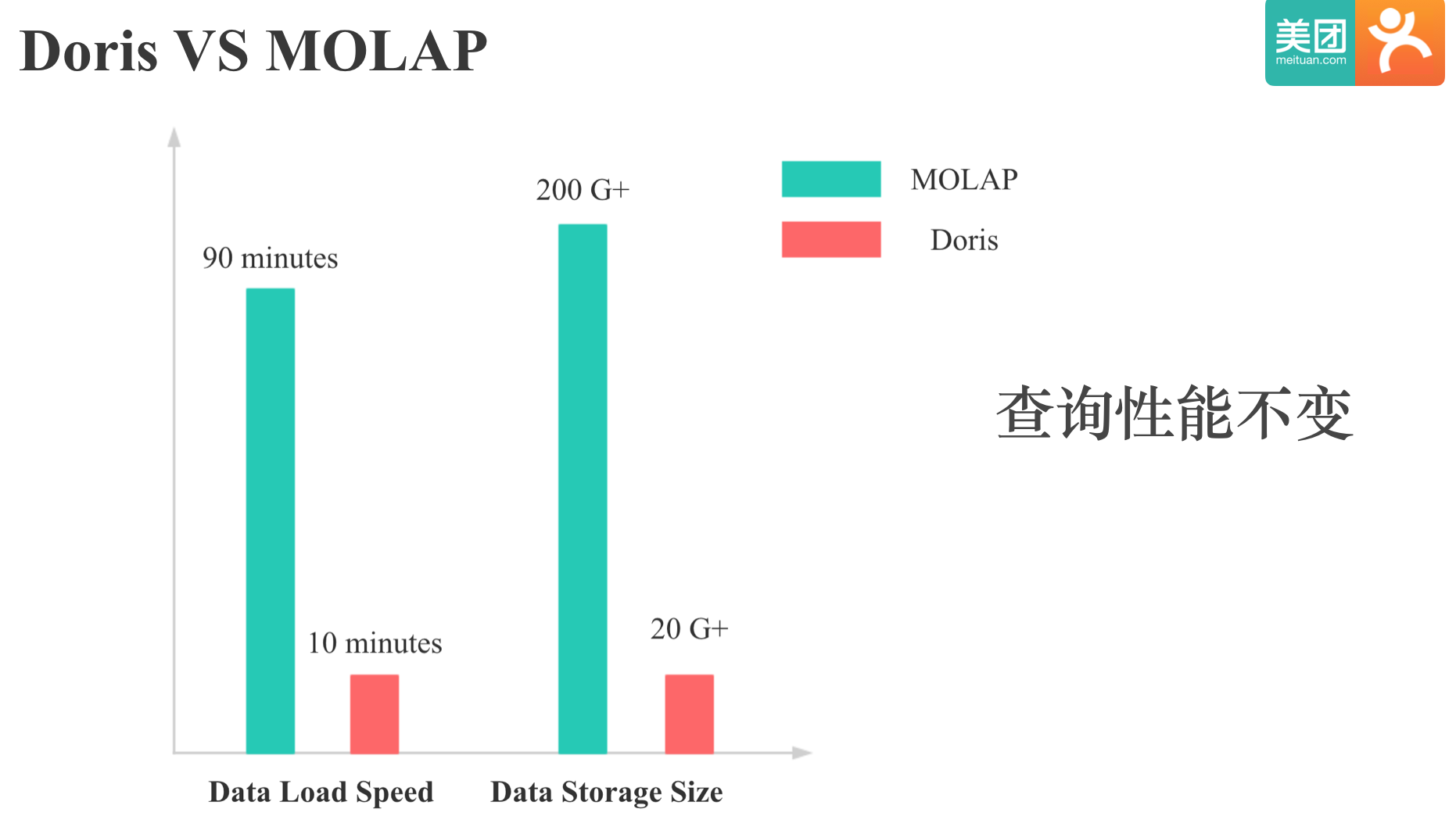
上图中展示的是 Doris 和 MOALP 系统对同一个商家分析应用在数据导入和数据存储方面的对比,可以看到,在保持查询性能不变的前提下,Doris 在导入速度和存储效率上都有了很大的提升。
明细 + 聚合
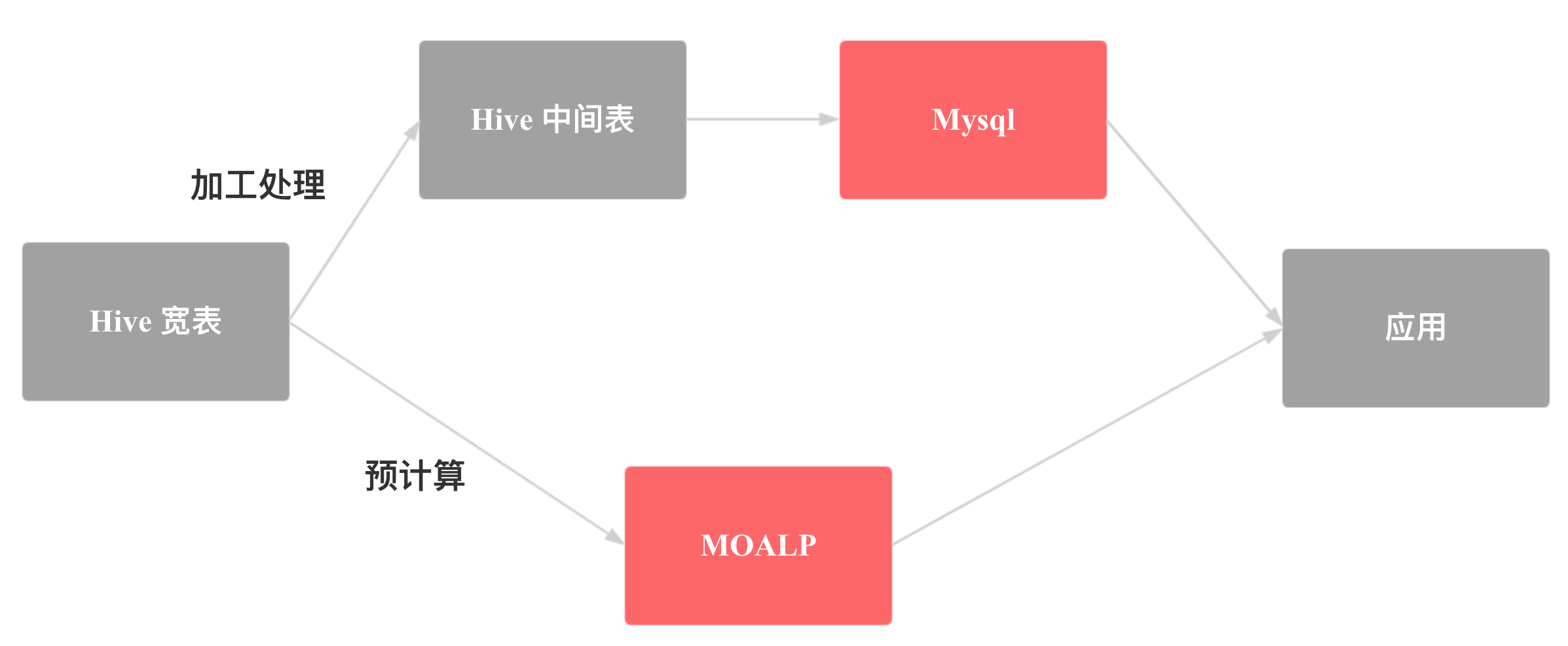
同时查询明细和聚合是用户比较常见的需求,但是由于 Kylin 和 Druid 不能支持明细查询,所以用户就需要用 Mysql 或者 ES 来满足明细需求,再用 Kylin 和 Druid 来满足聚合需求,这样就有两条开发链路,数据也有冗余,并且可能还会有数据一致性的问题。
有了 Doris 之后,我们只需要 Doris 一个引擎就可以同时 Cover 明细 + 聚合的需求,用户的开发流程就会简化许多。
外卖准实时数仓
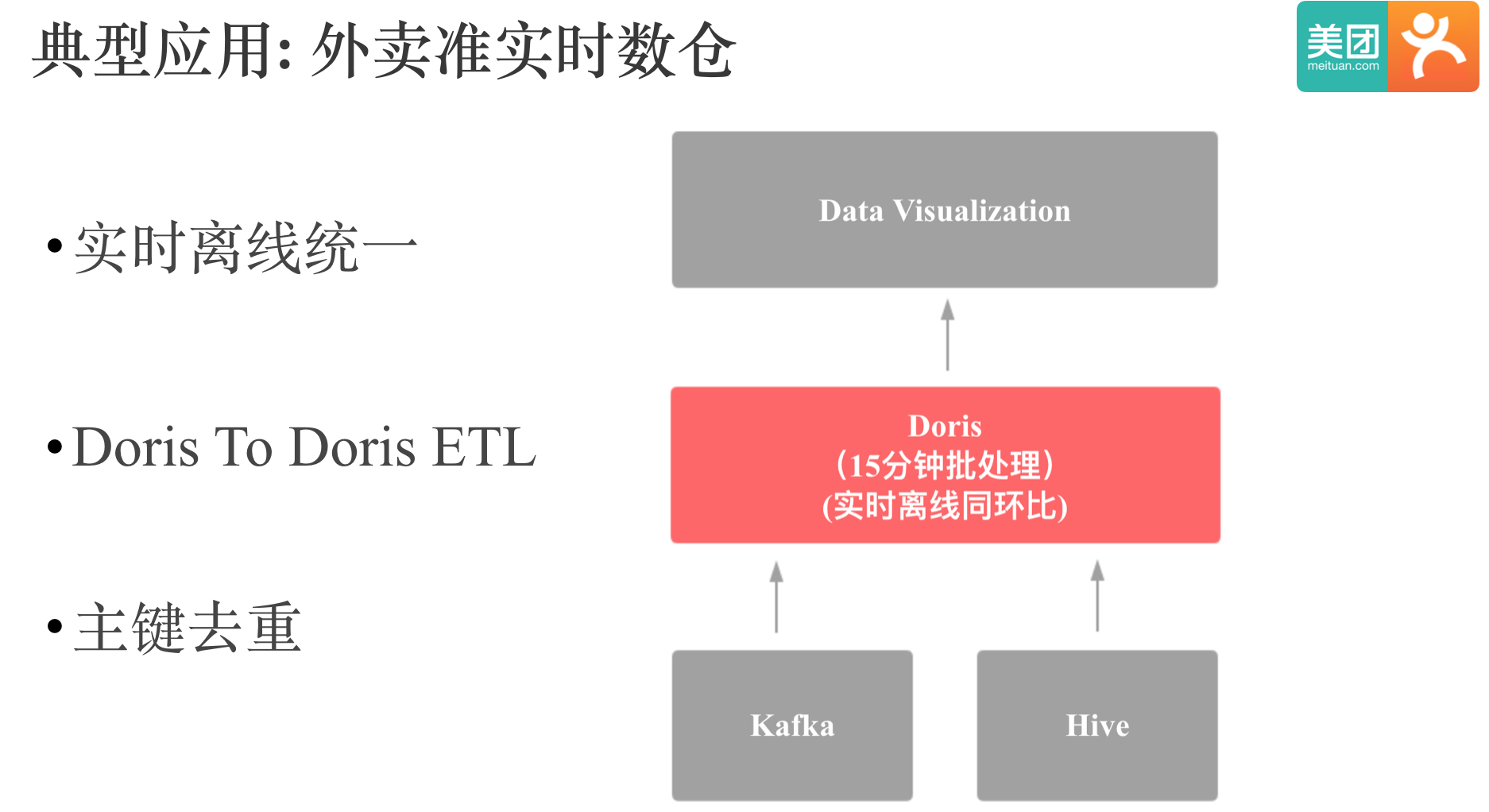
上图中是我们外卖准实时数仓的一个示意图,数据会从 Kafka 和 Hive 进入 Doris 中,然后每 15 分钟会通过 Doris to Doris ETL 计算实时和离线的同环比(外卖的特殊业务需求)。
这个应用中主要依赖了 Doris 以下特性:
- 同时支持实时和离线数据导入。
- Doris To Doris ETL, 这个指的是 Doris insert into select 的功能
- 还有一个是主键去重,建模时用的是 Doris 的 UNIQUE KEY 模型,Doris 的主键去重和主键更新也是我们用户广泛使用的功能。
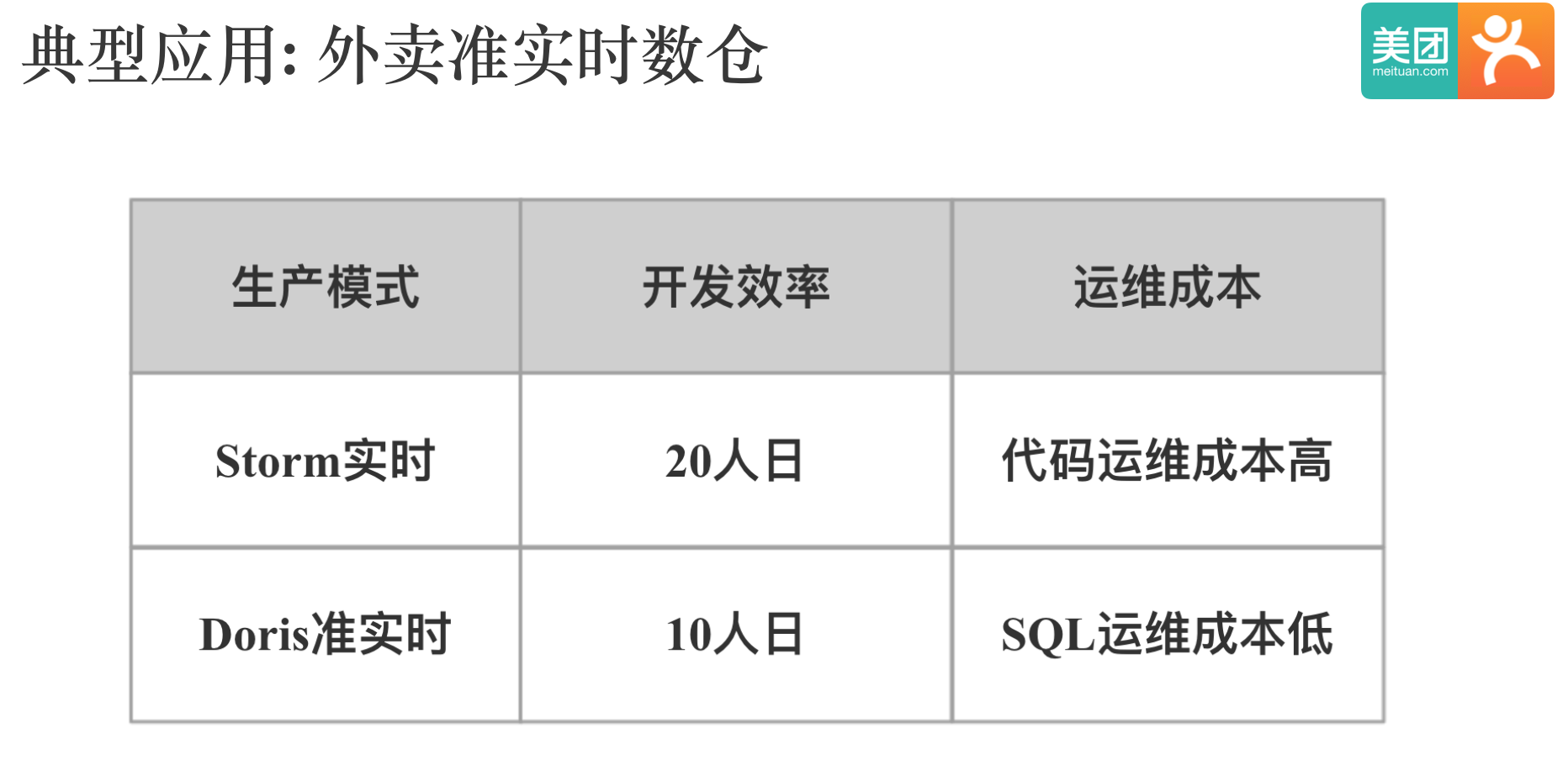
上图中展示的是我们外卖基于 Doris 构建准实时数仓,和基于 Storm 构建的实时应用的开发效率对比,用 Storm 开发需要 20 人日,用 Doris 开发需要 10 人日,这个效率的差别应该主要来自写 SQL 和写代码的效率差别。
转载请注明出处:数据仓库【十三】:数据仓库选型,Doris
原文地址:https://www.xiaotanzhu.com/%E6%95%B0%E6%8D%AE%E4%BB%93%E5%BA%93/2022-07-13-dw-doris.html